
GTA 6 Trailer Segmentation Using Deep Topological Analysis
We provide an illustration of video analytics utilizing Deep TDA (Topological Data Analysis)
Let's break down what's happening in this video and grasp the process. This is a new way to analyze videos, and it provides a clear example of how image segmentation functions in Deep Topological Analysis.
Frame extraction
The first thing is to extract frames from the video, and it's not too complicated; a simple Python code can do it. For a 1 minute and 24 seconds video at 30 frames per second, we end up with around 2590 frames. After trimming some similar frames at the start and end, we end up with our list of frames.

Extracted frames from the video
Model training
To create the visuals, we utilized our Deep TDA model, beefed up with contrastive learning. The training process took place over 100 epochs, resulting in a solid model ready for analysis.
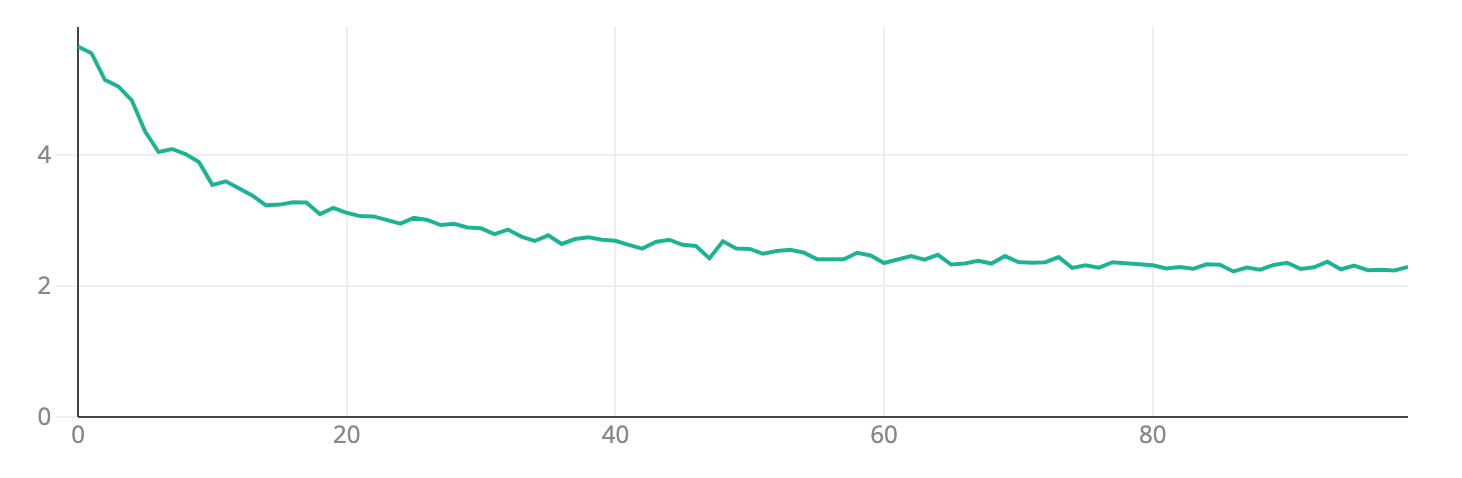
Analysis
Looking at the segmentation results from various angles, starting with the graph's high-level representation, it's evident that there are distinct regions for similar visual themes:
- Social media: Frames extracted from "social media" feeds,
- Water: Frames featuring water scenes,
- Landscapes: All visual elements associated with nature, landscapes, and cityscapes,
- Face closeups + logo scene: Human faces display unique patterns, and the model effectively grouped them together. Additionally, a prolonged scene with a logo against a black background was accurately positioned in this category.
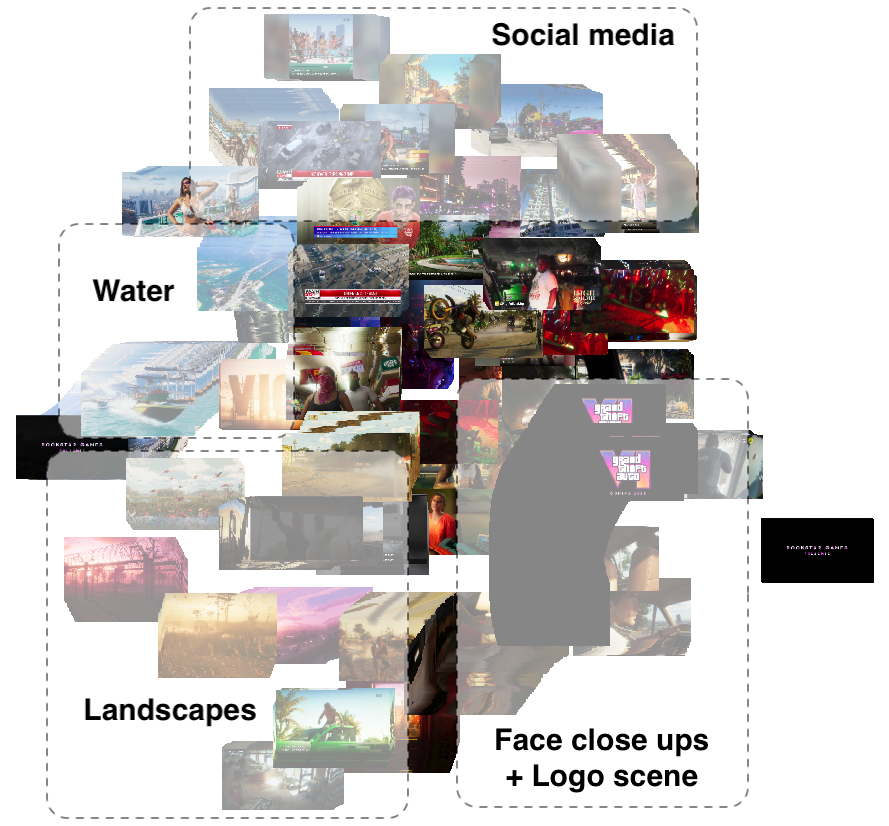
Observing the overall structure, a noticeable dependency emerges: the longer the scene, the more extended the trace. In the trace, represented as a line, scenes with continuous transitions to new states are depicted. On the other hand, scenes that linger around a specific subject without much transition are illustrated as round traces.

TDA map on 2D plane with frame positions
Long scene traces
Certain extended scenes in the video represent a seamless shift from one position to another, a characteristic depicted as a trace in the TDA map. Here's an example of such a trace at the beginning of the video:
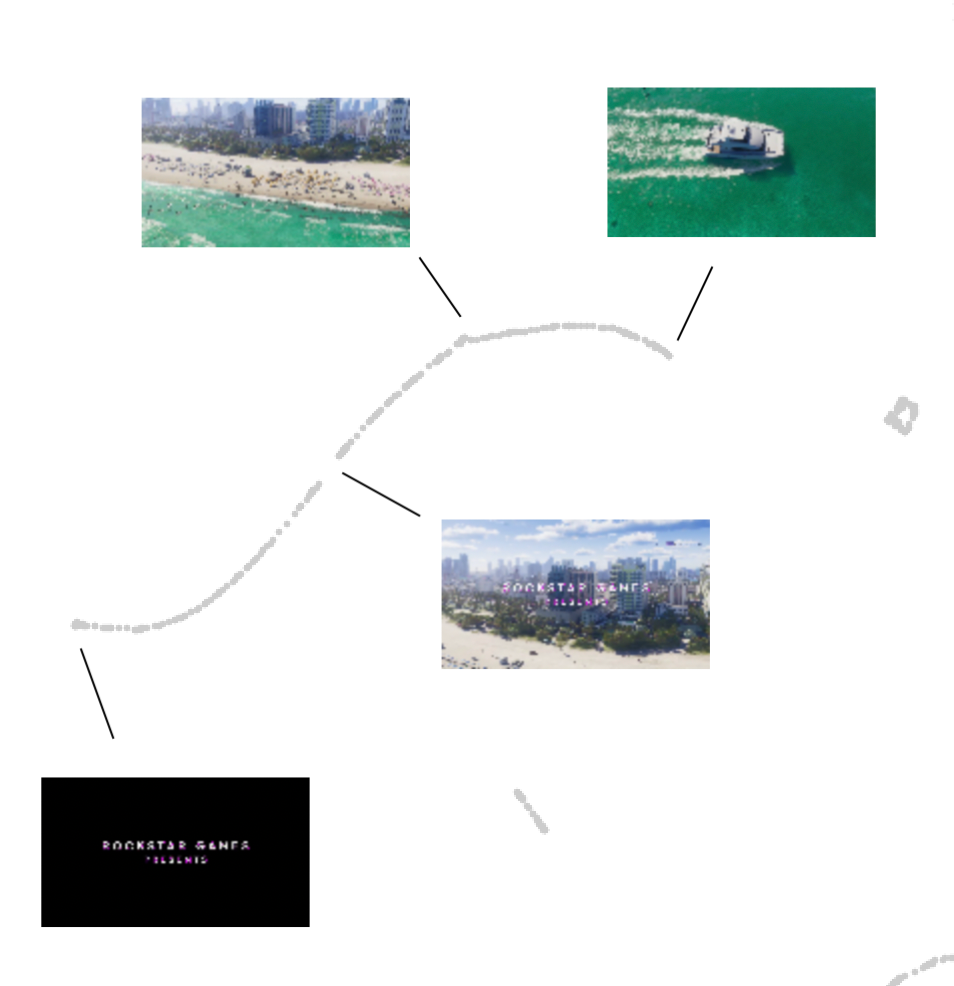
Here a part of the video for the reference:
Y-shaped trace
Another intriguing structure we observe is the Y-share, known in TDA terms as a junction. This represents a scenario where three patterns or features converge together:
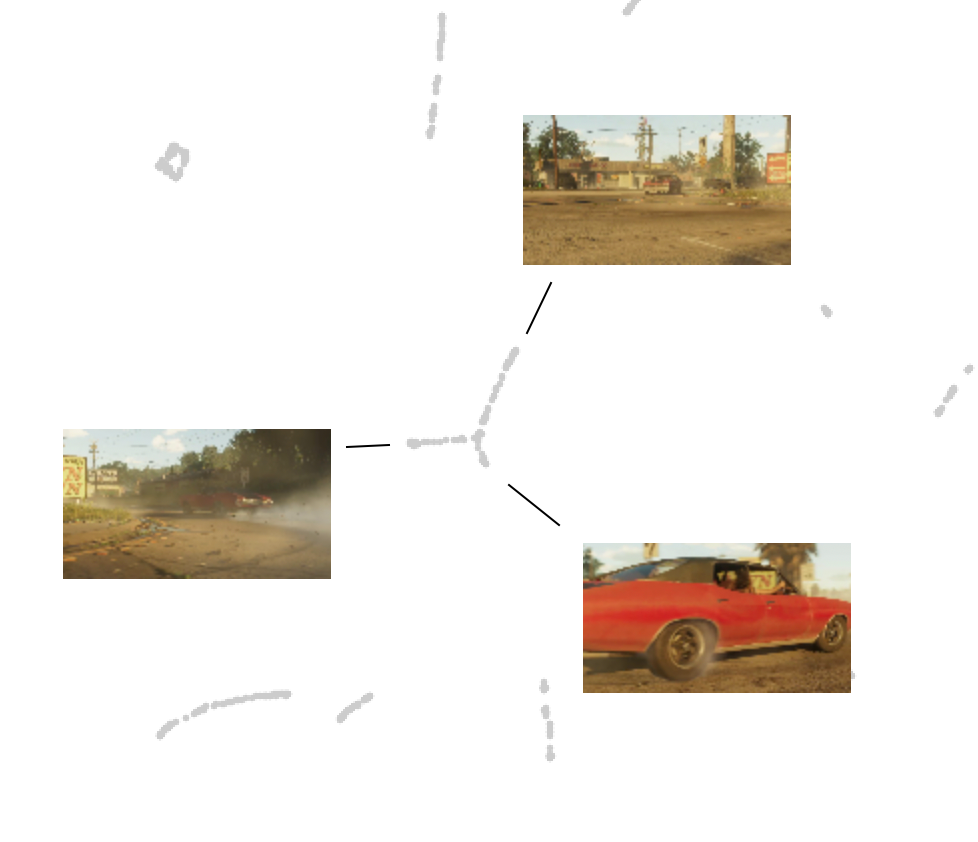
Once more, let's take a look at this specific segment from the video:
There are numerous other fascinating structures waiting to be explored; feel free to examine them in detail.
Conclusion
Deep TDA proves its applicability not only to short trailers but also to longer content videos, such as extensive collections from dashcams or cameras on self-driving cars, facilitating the segmentation of vast content into analyzable patterns.
Its versatility extends to large-scale production environments, enabling segmentation across various video types, including production lines, distribution, security, and more.
The original GTA6 Trailer and its frames are property of Rockstar Games.